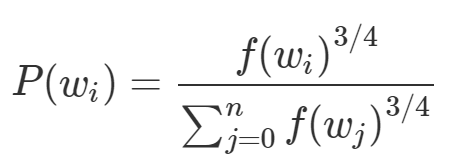word2vec는 one-hot-vector의 한계를 극복하기 위해 등장한 개념이다. 이는 중심 단어(center word)가 주어졌을 때, 주변 단어(context word)가 나타날 확률을 계산하고 window 내에 주변 단어가 나탈 확률의 곱을 최대화하도록 학습을 하게 된다.
word2vec의 objective functionword2vec 원리
word2vec의 objective function은 P(o|c)가 되고, 우변의 v는 입력층과 은닉층을 잇는 가중치 행렬 W의 행백터, u는 은닉층과 출력층을 잇는 가정치 행렬 W′의 열벡터이다. 분모는 주변 단어에서 등자하지 않는 단어와 중심 단어의 코사인 유사도를 의미하며 분자는 주변 단어에 등장한 단어와 중심 단어의 코사인 유사도를 의미한다. 따라서 word2vec의 학습은 주변 단어와 중심 단어의 유사도는 높이면서 주변 단어에 나타나지 않는 단어와 중심 단어 간의 유사도를 낮추는 방향으로 학습을 진행하게 된다.
word2vec parameters and computations
word2vec은 CBOW와 Skip-gram 두 가지로 이루어져 있는데 assignment2가 Skip-gram을 구현하는 것이니 Skip-gram 작동 방식에 대해서 알아보도록 하쟈 :)
문서로부터 사용된 단어 wt를 모두 추출하여 one-hot encoding W를 만든다.
학습할 word embedding Winput를 랜덤 초기화한다.
scoring을 위한 WToutput를 랜덤 초기화한다.
forward 연산을 진행한다.
cross-entropy를 이용하여 손실 값을 계산한다.
gradient descent를 계산하여 backward를 진행한다.
gradient descent의 결과에 따라 파라미터 Winput와 WToutput를 업데이트한다.
Skip-gram model structure
근데 Skip-gram의 세부 내용에 대해서는 여기를 참고하는게 더 좋고.. word2vec의 backward연산에 대해서만 알아보도록 하겠다.
이후 이 값을 가지고 backward의 연산이 진행됩니다. 위의 예를 보면, 맨 왼쪽의 Vx1의 벡터는 단어의 one-hot vector를 의미하고 그 길이 V는 단어의 총 갯수로 정해집니다. 그리고 dxV는 2에서 center word의 word embedding 파라미터를 초기화한 부분입니다. 여기서 d는 embedding size이고 곱해지는 부분은 center word의 representation한 부분이라고 생각해도 됩니다. ( one-hot vector의 특성상 그 외는 0으로 곱해지고 저 부분만 1로 곱해지기 때문입니다. ) 그 이후로 Vxd의 부분에 해당하는 scoring부분이 진행되어 Output word representation을 합니다. 이 후 softmax를 취해 이를 확률 분포로 바꾸어주고 cross entropy를 진행합니다. 이 과정은 아래의 사진에 잘 나와있습니다. 그림 출처 : https://cs231n.github.io/linear-classify 위에서 출력값은 [-2.85 , 0.86, 0.28] 이었는데, 우리가가지고 있는 정답 y는 [0, 0, 1]과 같은 확률분포 이기 때문에, softmax 함수를 사용해서 0~1사이의 값을 갖는 확률 분포의 형태로 바꿔주게 됩니다. ( 파란색 1과 2를 거친 부분입니다. exp를 하는 이유는 이전에 log를 취했기 때문에 ) 이렇게 반환 된 결과 softmax(z) = [0.016, 0.631, 0.353]을 cross-entropy를 사용해서 [0, 0, 1]과의 오류에 대한 피드백을 하게 됩니다. yi의 대부분이 0이기 때문에 1인 부분만 남게 되고 -log(0.353)을 가지게 됩니다.
이후 이 값을 가지고 backward의 연산이 진행됩니다.
위의 그림을 보면 1번째 사진에서 objective function을 정의하고 이를 미분합니다. (gradient descent 계산) 그 결과는 2번째 사진인데, log의 성질로 나누기를 빼기로 바꾸고 각각에 대해 미분을 해서 결과를 얻은 것을 볼 수 있습니다. 이 과정에서는 chain rules가 들어가는데 이는 아래의 ratsgo님의 블로그글로 다시 정리해보도록 하겠습니다.
2. Optimization: Gradient Descent
위의 목적함수를 최소화하는 값을 찾기 위해 Gradient Descent 방법을 사용합니다. 이는 임의의 초기값이에서 하이퍼파라미터값인 learning rate만큼 이동하면서 최저점을 찾아가는 방법이다.
Cost function을 Minimize하는 방법
이를 수식과 코드로 나타내면 다음과 같다.
하지만 비용 함수는 각각의 중심단어가 가지는 모든 주변 단어에 대해 진행해야 하므로 계산량이 많다. 이를 보완하기 위해 Stochastic Gradient Descent(SGD)라는 방법을 사용한다. 이는 loss function을 계산할 때, 전체 데이터 대신 일부의 데이터에 대해서만 loss function을 계산하는 방법이다. 이를 통해 빠른 속도로 학습을 진행할 수 있었지만 window에 대해 SGD를 적용할 때, word2vec에서 사용하는 데이터가 매우 sparse하다는 문제점이 있다. 이게 문제가 되는 이유는 데이터 특징때문에 sparse matrix가 생성되어 계산의 효율성이 떨어지기 때문이다. 이때 sparse matrix란 행렬의 대부분의 요소가 0인 행렬로, 주변 단어에 해당하는 것 말고 나머지 단어들이 전부 행렬값이 0으로 채워지기 때문에 이러한 문제가 발생하게 된다. 그래서 word2vec에서는 SGD말고도 효율성을 높이기 위해 subsampling frequent words과 negative sampling이라는 2가지 방법을 사용한다.
3. Subsampling frequent words
word2vec에서 학습해야 하는 Winput와WToutput는 각각 크기가 V×N,N×V이다. 보통 corpus에서 등장하는 단어수는 약 10만개라는 것을 고려하면 embedding dimention이 100차원만 되어도 2000만개나 되는 많은 숫자를 구해야 한다. 따라서 단어 수가 늘어날 수록 계산량이 증가한다. 앞서 언급했던 것 처럼 이러한 계산량을 줄이기 위한 벙법 중 하나다 subsampling frequent words이다. 이는 특정 단어를 학습에서 제외시키는 것으로, 특정 단어(wi)를 학습에서 제외시키기 위한 확률을 다음과 같이 정의한다.
f(wi)는 해당 단어가 말뭉치에 등장하는 비율을 말하며 t는 하이퍼 파라미터 값이다. 따라서 빈도가 높은 단어일수록 제외될 확률이 높다. 이러한 subsampling 방법을 통해 학습량을 줄여서 계산량을 감소시킨다.
4. Negative sampling
word2vec는 출력층이 내놓은 스코어 값에 softmax 함수를 취하여 확률값으로 변환한 후 정답과 비교한다음 backward 과정을 진항한다. 하지만 softmax를 적용하려면 중심단어와 나머지 모든 단어의 내적을 진행한 뒤 exp를 취해 계산량이 많아지게 된다. 따라서 softmax확률을 구할 때 전체 단어를 대상으로 하는 것이 아니라, 일부 단어만 뽑아서 계산을 하는 negative sampling이 제안되었다. 이는 window size 내에 등장하지 않는 단어를 뽑고, 정답 단어와 합친 후 이에 대해서만 softmax 확률을 개상하는 것이다. window 내에 등장하지 않은 어떤 단어 (wi)가 뽑힐 확률은 아래와 같이 정의된다.
어렵다... 영어는 너무 나도 어렵다... 강의를 듣는데 15분마다 존다... 블로그들의 도움을 받아서 포스팅을 올리기는 하지만.. 진짜 너무 졸렸다..